Deep Autoencoder for Combined Human Pose Estimation and Body Model Upscaling
Matthew Trumble1, Andrew Gilbert2, Adrian Hilton 1 and John Collomosse 1,3 1Centre for Vision, Speech & Signal Processing University of Surrey, United Kingdom 2Department of Music & Media University of Surrey, United Kingdom 3Creative Intelligence Lab, Adobe Research appeared atEuropean Conference on Computer Vision (ECCV'18)
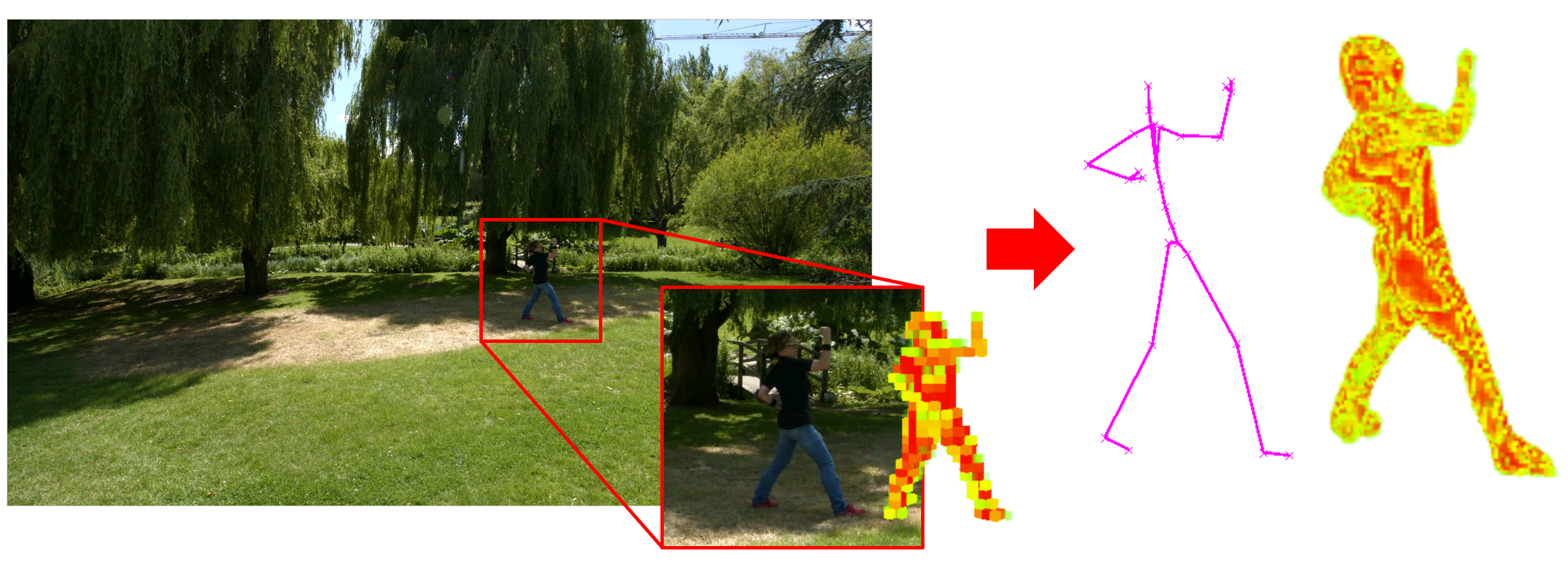
Abstract
We present a method for simultaneously estimating 3D human pose and body shape from a sparse set of wide-baseline camera views. We train a symmetric convolutional autoencoder with a dual loss that enforces learning of a latent representation that encodes skeletal joint positions, and at the same time learns a deep representation of volumetric body shape. We harness the latter to up-scale input volumetric data by a factor of 4 times, whilst recovering a 3D estimate of joint positions with equal or greater accuracy than the state of the art. Inference runs in real-time (25 fps) and has the potential for passive human behaviour monitoring where there is a requirement for high fidelity estimation of human body shape and pose.
Paper

Deep Autoencoder for Combined Human Pose Estimation and Body Model Upscaling
Matthew Trumble
Andrew Gilbert,
Adrian Hilton and
John Collomosse
ECCV 2018
![]()
![]()
Citation
@inproceedings{trumble:eccv:2018,
AUTHOR = "Trumble, Matthew and Gilbert, Andrew and Hilton, Adrian and Collomosse, John ",
TITLE = "Deep Autoencoder for Combined Human Pose Estimation and Body Model Upscaling",
BOOKTITLE = "European Conference on Computer Vision (ECCV'18)",
YEAR = "2018",
}